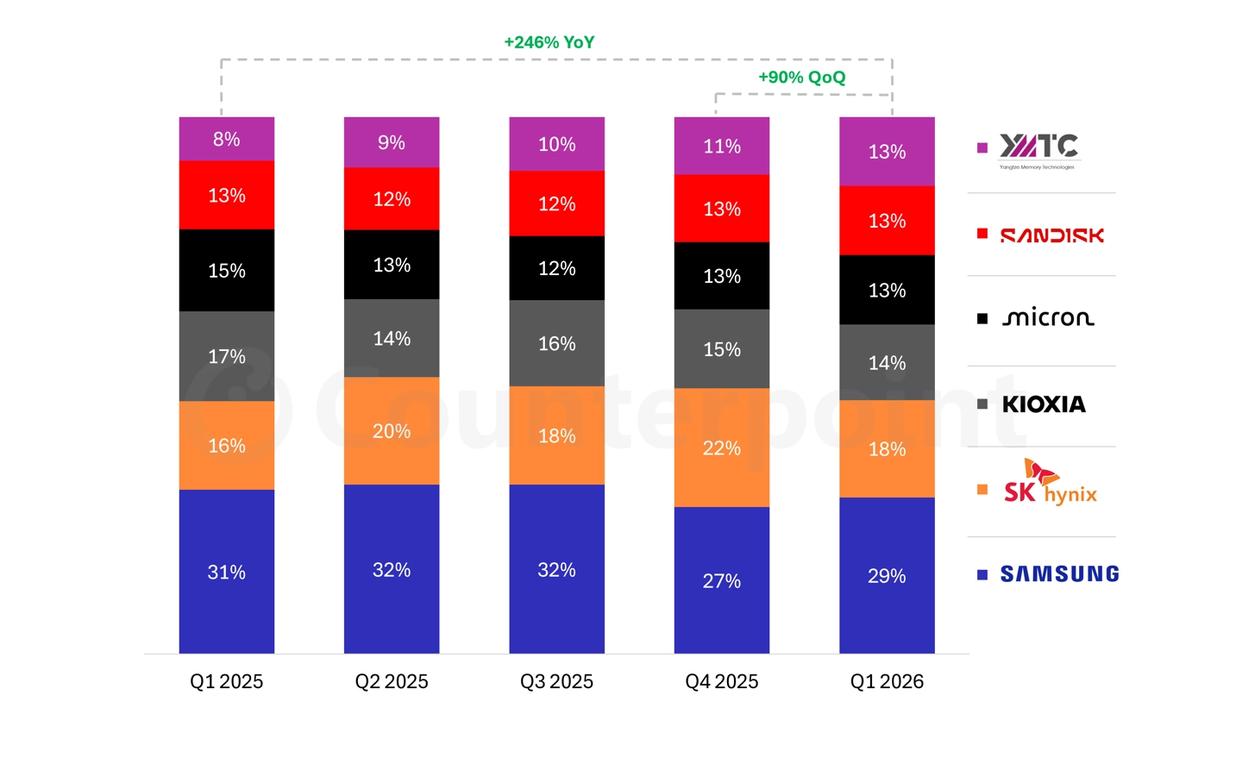
铠侠在国际会议ISSCC2025展示了1TB 3b/Cell BiCS闪存的开发™Generation10 产品。该产品由铠侠和新德公司联合开发,是一款高内存密度的三维闪存,规模良好,可达29Gb/mm2采用332条世界线叠加和布局优化技术,实现了1Tb产品中最高的比特密度和最小的芯片尺寸。除了引入Toggle DDR 6.0外,新接口(IF)电路和读取操作方式实现了4.8Gbps的数据传输速率,并提升了29%的读能耗。以下是从三个技术角度的简要介绍。
布局技术
该产品引入了与传统产品相同的CBA(CMOS直接绑定阵列)架构。然而,四个平面是垂直方向排列的[1]这和之前的产品不同。该平面图减少了粘结垫(BP)面积,并使悬垂面积减半[1](图1(a))如图1(b)所示,最低的电阻板层施加在记忆单元阵列芯片和CMOS芯片的顶层金属层上,这些层通过BWWPC有效连接[1] (B 垫子用于 W向 W向 P或 C方向)。强大的电力网络带来了高面积效率,电路压缩和电路性能的提升。
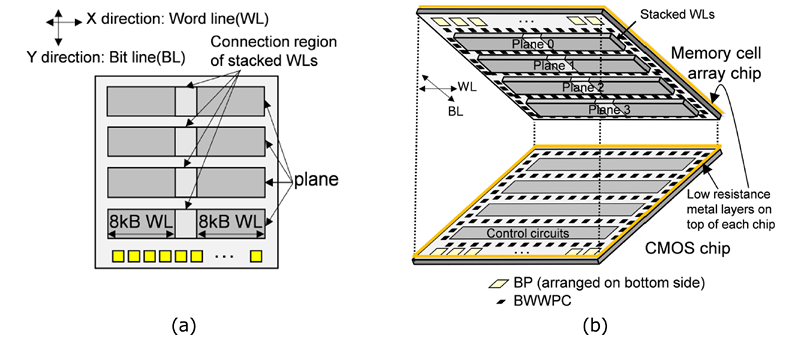
图1(a)平面图图像,(b)2025年IEEE CBA芯片©的剥开视图 接口技术
采用非匹配DQS的IF架构如图2(a)所示。在V REF中,P在输入接收器中使用P-P,用于使用每个DQ的最优参考,并据我所说的2路T-D-Eedback Equalizer(2TI-DFE)与D的Ata-Driven Self-R eset(DDSR)电路进行了新近采用。2TI-DFE与DDSR的示意图见图2(b),时序图见图2(c)。4TI-DFE是DRAM接口中著名的技术,用于改善数据输入裕度,但每个DQ需要4个感应放大器(S/A)电路,这会导致能耗和开销增加。该产品新引入了DDSR电路,可以保留决策,楼主O、OMO直到下午1点E以及1ME变化由3输入NAND门检测,避免反馈误差[1].因此,我们通过减少交错空间数量实现了降低能耗和面积开销[1]DFE从4降到2。
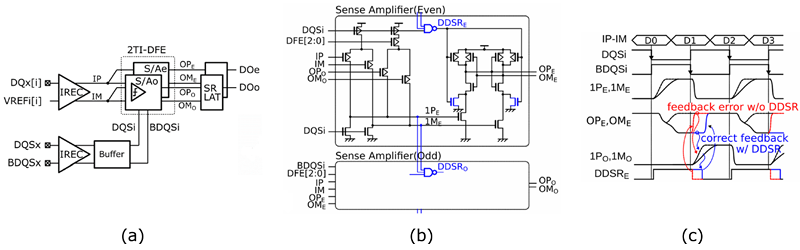
图2 (a) 带非匹配DQS的IF架构,(b) 2TI DFE带DDSR原理图,(c) 2025年IEEE 时序图 ©
图3展示了所有DQ的shmoo图[7:0]。我们确认2TI-DFE和PPVT对4.8Gbps的数据传输速率有贡献。
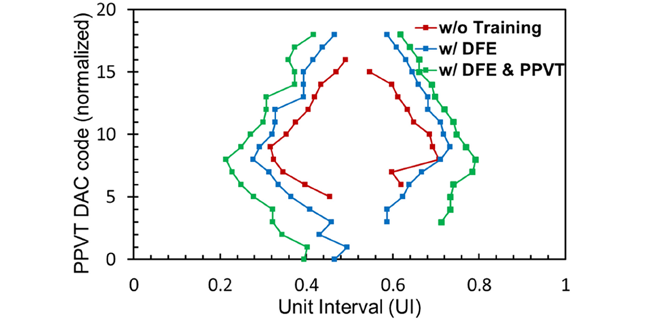
图3 2025年所有DQ[7:0]©的Shmoo图 CORE 读取性能改进技术
由于高度堆叠的WL,未选中WL的充电是增加读取时间(tRead)和电流消耗的主要因素[1]处于阅读操作中。为了解决连续读数中的这些问题,我们应用了白点电压-摆幅减少控制,如图4所示。在传统的连续读写中,未选定的白点电压在VSS与由电荷泵产生的读电压电平(Vread)之间发生变化[1].在这项工作中,在读取第一个 WL 的读数后,我们将 VREAD 放电到一个中间电位,这个电位高于 VSS。然后我们从这个中间电位充能到VREAD,为下一次读写做准备[1].由于未选定的WL的电压摆幅较小,可以缩短Vread的设置时间和下一次读取操作的电流消耗。
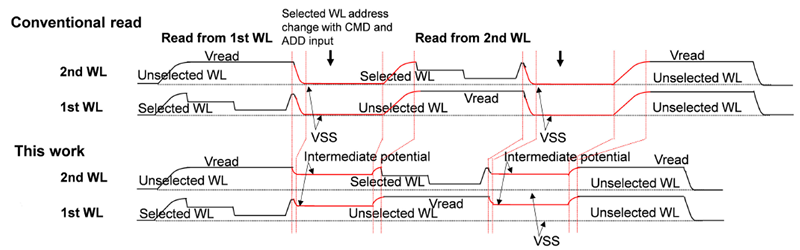
图4 2025年IEEE 操作波形 ©
图5(a)显示我们提出的方案将tRead减少4微秒,对应10%的改进[1].图5(b)显示了读能效率,显著提升了29%[1].
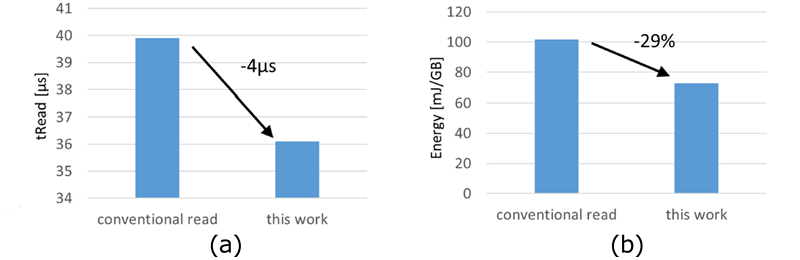
图5 (a) tRead 比较,(b) 2025年IEEE 能源比较 ©
我们成功开发出一种面积和节能的3D闪存[1]引入了高度堆叠的布局优化技术,采用高速接口和低功耗电路设计技术。我们致力于提供高性能、高容量的闪存,并持续电路设计,同时努力降低功耗。